我是如何写一款社工工具的

生活在互联网时代的我们都喜爱社交媒体,甚至于这已经成了生活中的必需品。曾给大家介绍过 sherlock,但它的功能局限较大,感觉远远不够。所以我做了这么件事儿来更好的找到各位。

🍺本篇文章大约需要4分钟来阅读,届时你或许将学到:
- 我所理解的人性漏洞
python实现多站点信息搜寻原理Github Action自动发布至PYPI与功能测试
0x01 人性的漏洞
为了让别人更好得认识自己,我们通常会将各类信息上传。出于 某种习惯 亦或懒癌,我们更偏向于使用 相同的用户名 来进行注册。
即便是受过良好网络安全教育的同学,也会出现大量 账号密码的一致 ,甚至是 同款头像、地区、昵称、备注 的情况。
且不管内容的真实度,他们依然可以带来一定的参考价值,尤其是在 关键信息内容交叉 的那一刻。
以上内容纯属个人经验所得
0x02 站点搜集
依照上一点我们可以知道,寻找个人足迹并不会太难。而信息的可信度一直都有这一种从量变引发质变的过程,说白了就是越多越好。接下来我们就来讲讲我们去哪儿些站点更值得我们去检索。
2.1 rank排行
rank作为站点排名的依据也同样反应出其受欢迎的程度,我们可以根据搜索引擎并以如下关键字进行搜索
top social media 2020 或 social media ranks 类似语法来获取相关站点的统计结果
当然这样做也存在非常耗时的几项缺点, 例如:
- 你需要对多个搜索结果进行整合处理
- 需要对每个站点进行可行性测试
2.2 配置转录
项目内可通过 python3 -m sharingan.common 即可生成配置转录文件 templates.py
开篇我也提到了 sherlock ,而在这个项目中就已经存在了一个常用社交媒体的配置文件,大约有500个站点可供参考。而在后期这也将成为我们的首选。
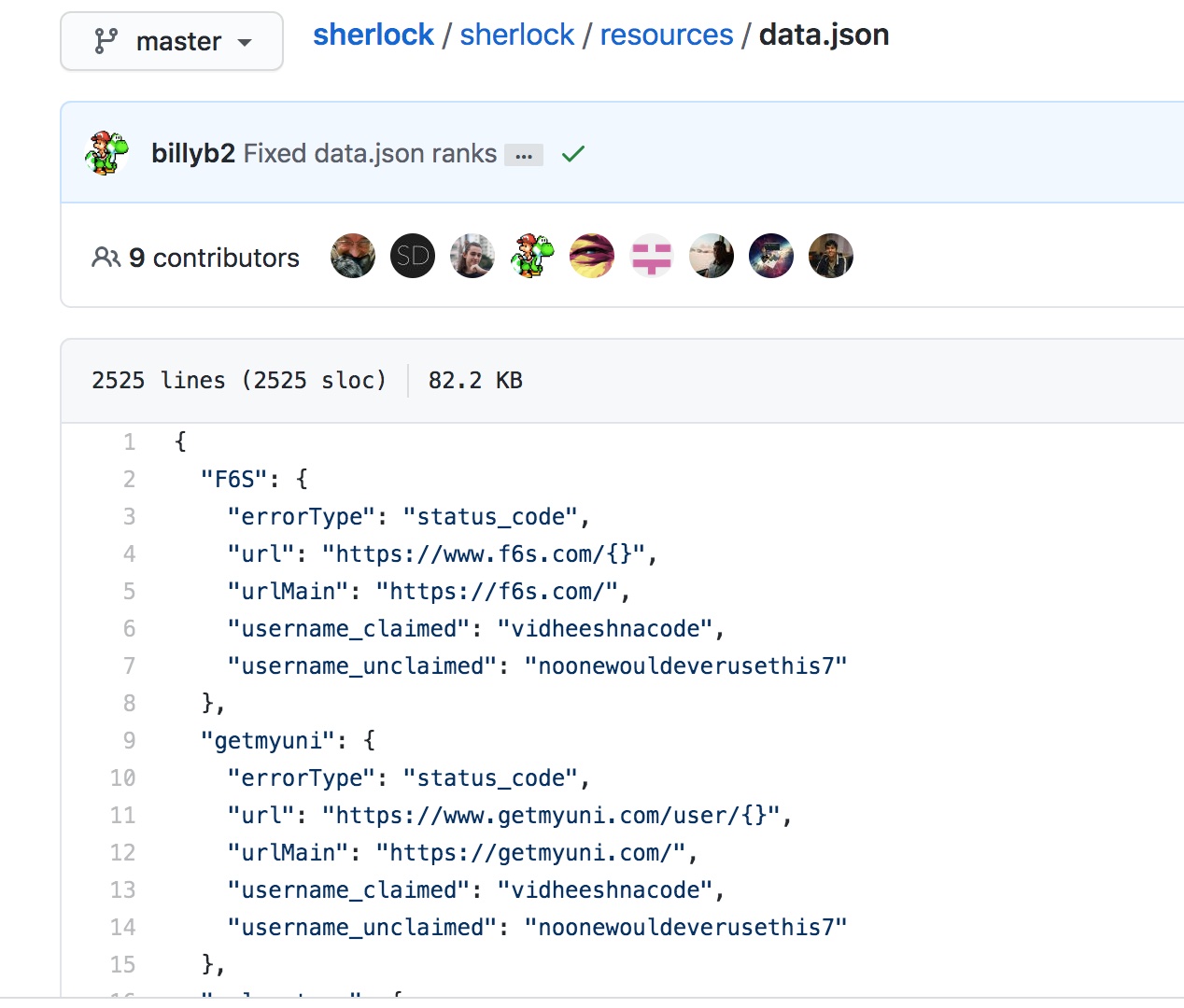
2.3 个人模型与站点配置建立
这里可能会有较为突兀的感觉
有了理念及目标,那就是时候讲讲如何定义一个人的身份了。我们应该很容易就能想到姓名、年龄、性别、地区等信息。于是我们编写如下代码,其中 extras 就作为额外的备选字段。
from dataclasses import dataclass, field
@dataclass
class person:
name: str = "未知"
age: int = 0
gender: int = 0
sign: str = ""
avatar: str = ""
locations: Set[str] = field(default_factory=set)
extras: Dict = field(default_factory=dict)
...
然后是对站点发送请求一般需要 链接、方法、载荷、代理、判断方法等等
@dataclass
class config:
url: str
method: str = "get"
data: str = None
json: str = None
headers: dict = None
cookies: dict = None
proxy: bool = False
lang: str = "en"
error_type: str = "func"
error_msg: str = lambda resp: resp.status_code != 200
再是判断用户名是否存在该站点的时候,肯定不止状态码这一种方法,于是我们定义多个方法
from httpx import Response
class error_types:
@staticmethod
def code(resp: Response, msg: int) -> bool:
# 根据状态码判断
return resp.status_code == int(msg)
@staticmethod
def text(resp: Response, msg: str) -> bool:
# 根据内容判断
return msg in resp.text
@staticmethod
def func(resp: Response, msg: object) -> bool:
# 自定义方法判断
return msg(resp)
0x03 定义解析方法
在完成模型类定义后,我们所需要做的就是将社交媒体站点集合进行实例化。由于该项目所涉及到的解析工作较为复杂,json无法胜任。于是我们将其变为一个类 Extractor。而类下的每个方法都代表一个站点, 配置信息则将通过 upload 方法上传,其中的可填字段则对应上文 config 类
def upload(*args, **kwargs):
return person(*(yield config(*args, **kwargs)))
class Extractor:
@staticmethod
def __site_name():
T = yield from upload(
{"url": "http://xxxx", "proxy": True or False, "skip": {}}
)
T.title = T.html.pq("title").text()
yield T
方法的工作流程如下:
这里非常绕,不要问我怎么写出来的。。外部工作流程简单的说就是扩展了一个for循环
- 配置信息进入
upload方法处理后将生成一个config实例 config实例将通过生成器 返回至外部- 实例与方法相关信息被丢入事件循环并开始作业
- 每个实例在被提取信息后生成有效载荷并发送请求获得响应
- 响应体及实例又通过生成器被发送回
upload方法内部 upload将接受到的数据以person类的方式进行了实例化 也就是变量TT开始根据自身html属性以一定的css路径去提取站点中的信息并赋值给自身- 在完成所有提取后,将
T返回给外部, 深藏功与名。
0x04 实例操作
在完成站点导入后,就基本完成了编写。于是我们任意输入一个账号例如 ruanyf 来进行测试,大家应该都知道是谁吧。
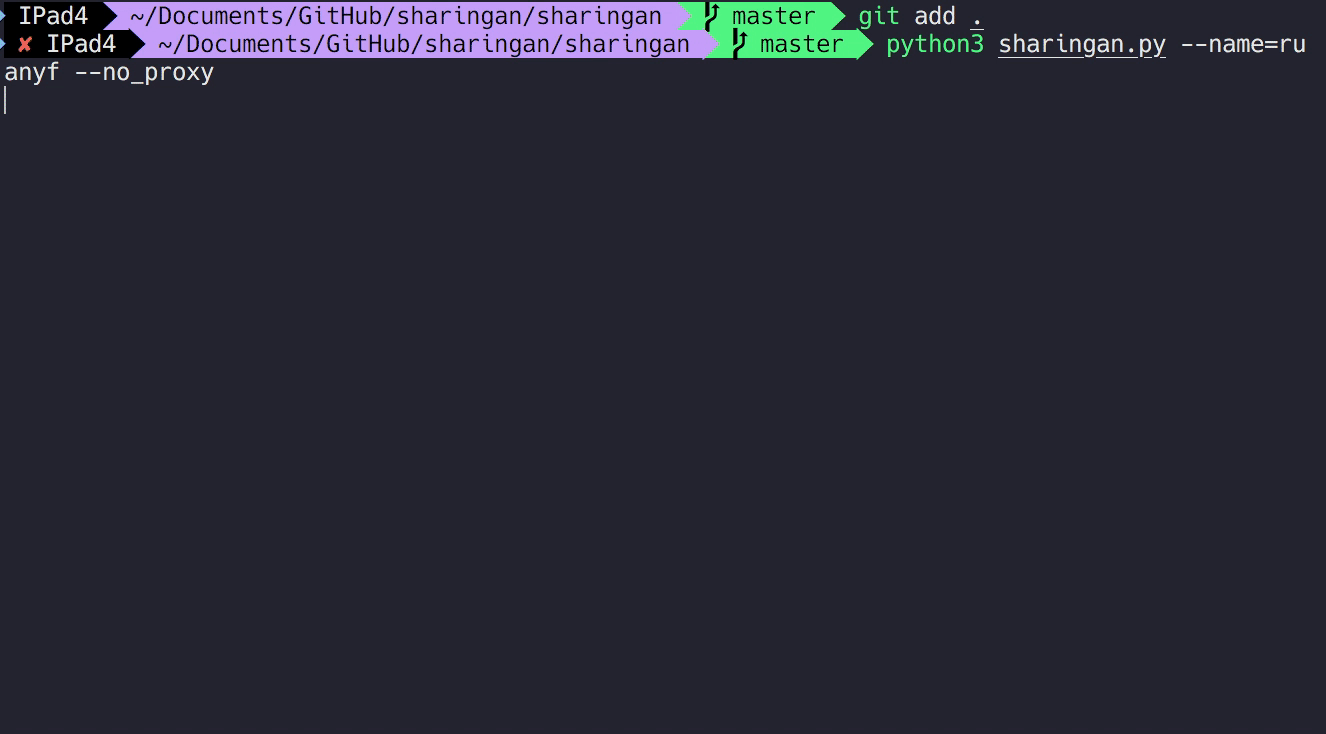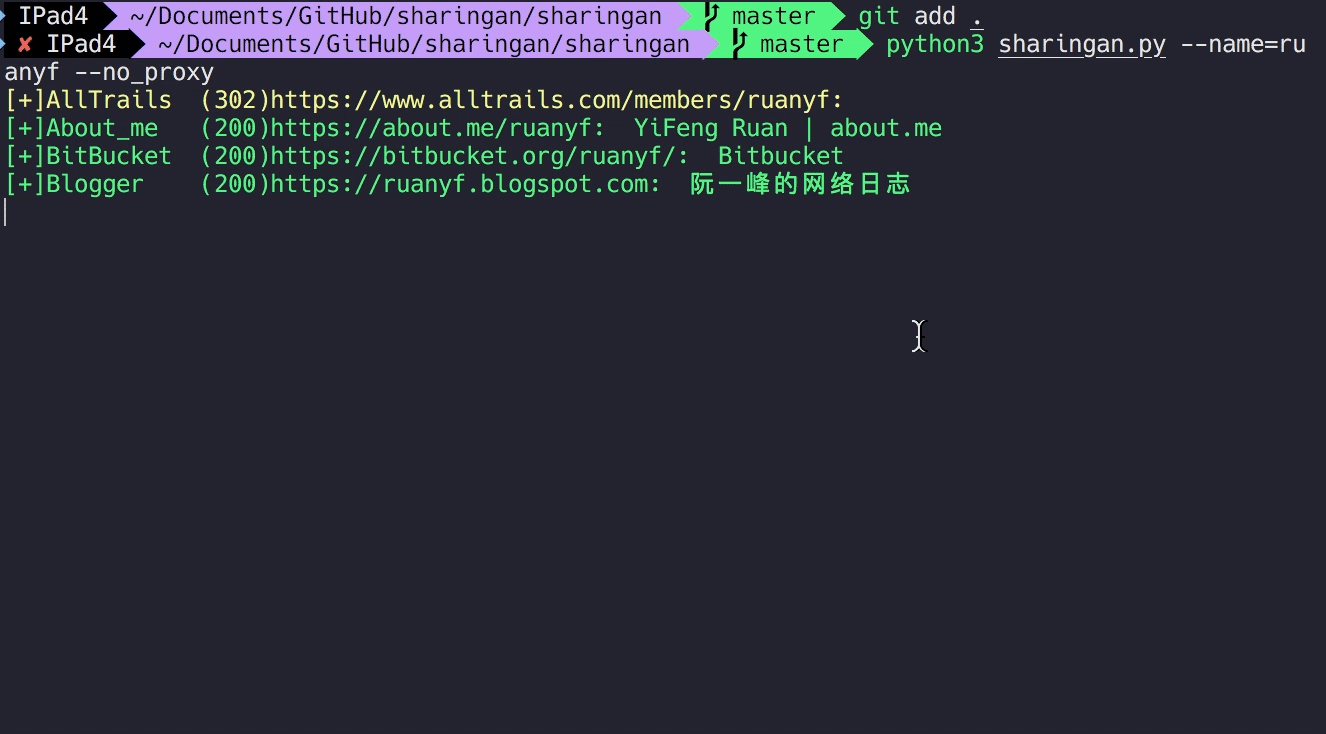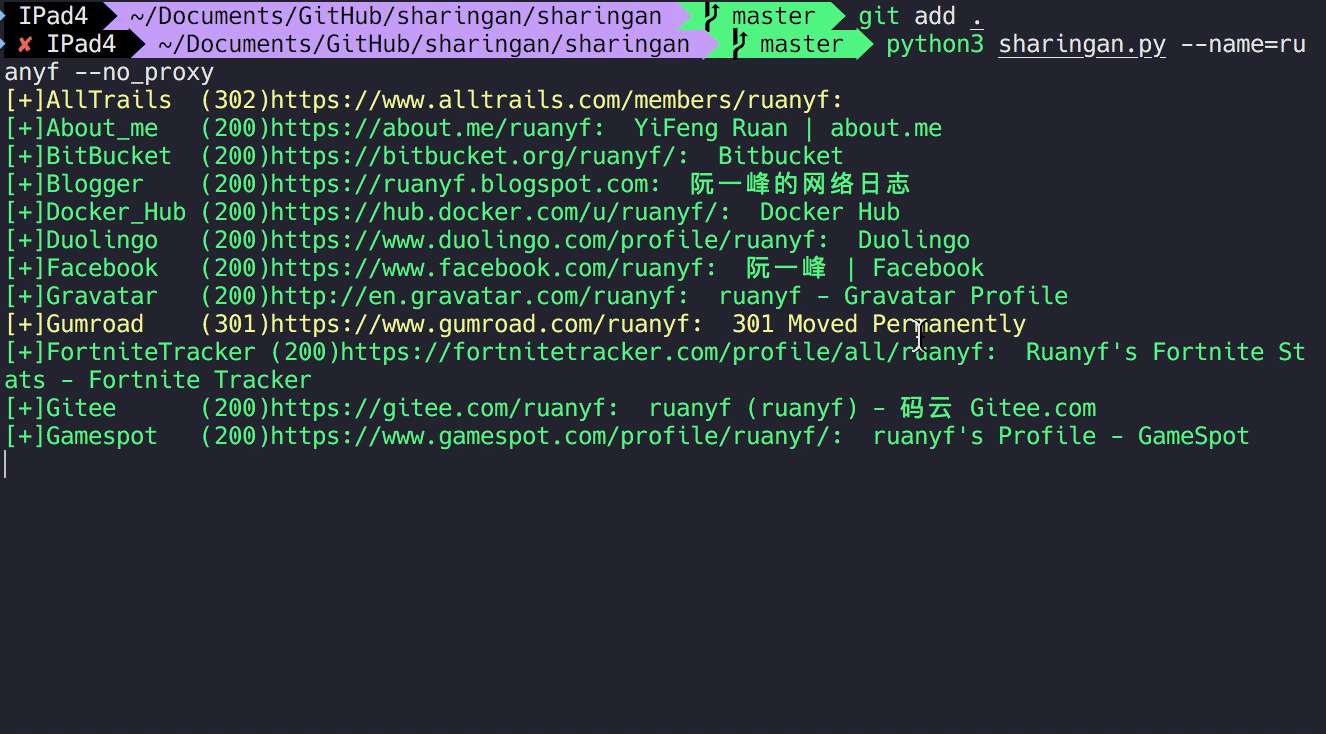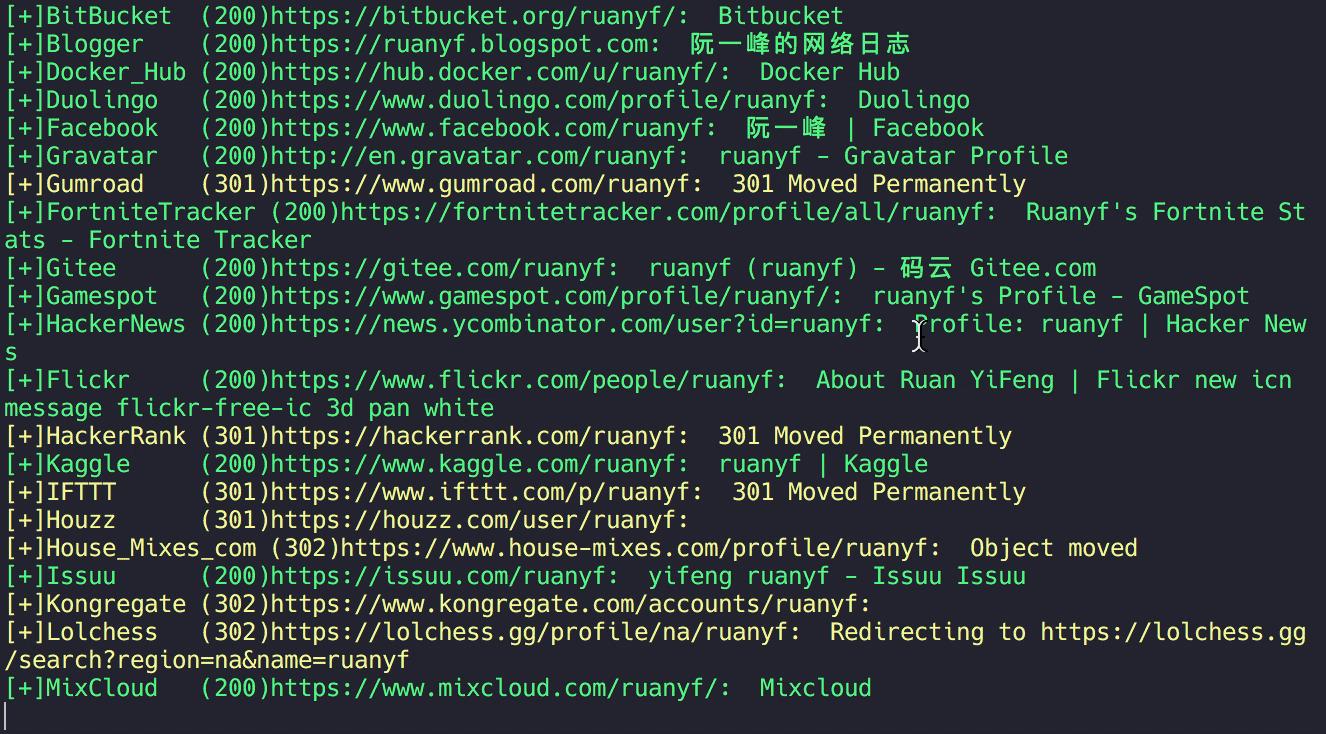
结果一会儿就出来了,由于绝大多数的站点都暂时是导入状态,所以只获取了标题而并未见有具体内容。当然这点也正在进一步的完善中。
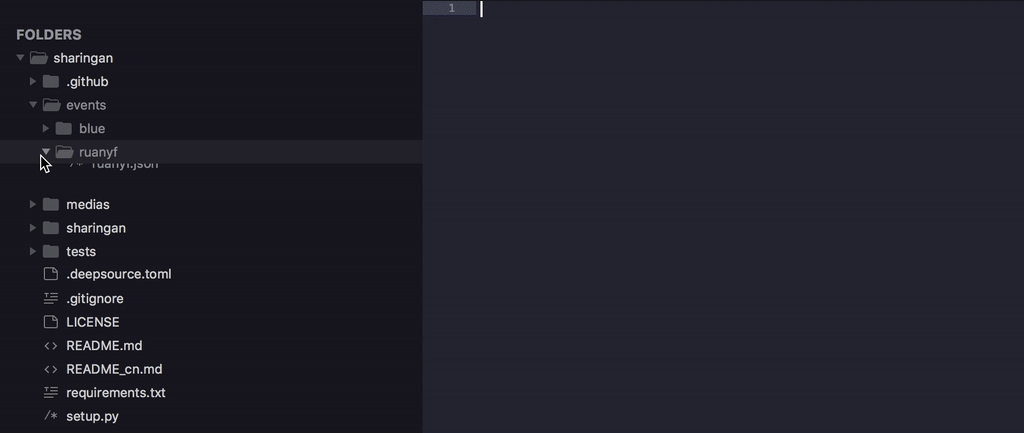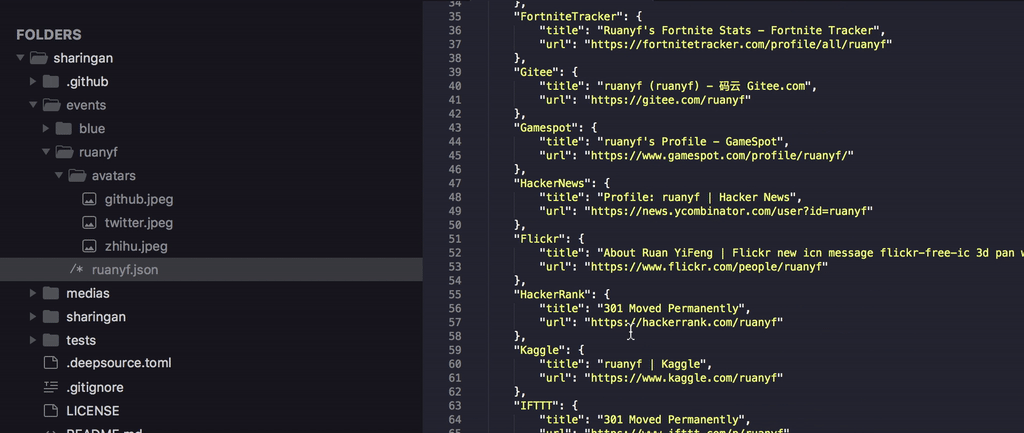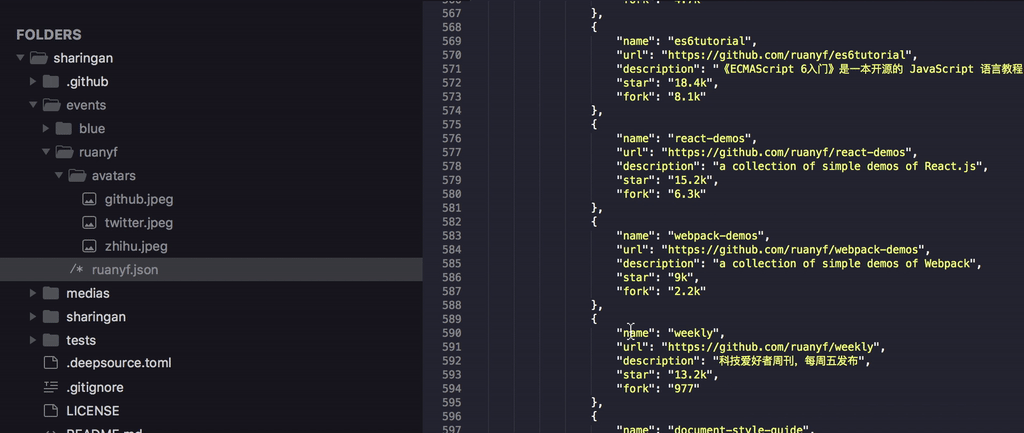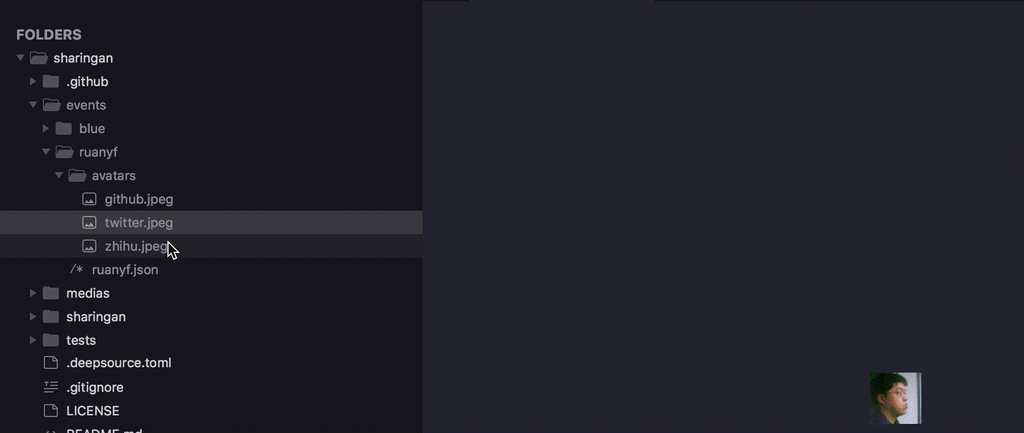
0x05 项目运行方式优化
规范化对于一个项目来说非常重要,能避免很多不必要的麻烦,例如源代码易于阅读、运行方式简单。也就是良好的用户体验。
5.1 模块化
为了将该项目作为一个模块来调用,类似这样
python3 -m sharingan
我们需要在目录下添加了 __main__.py 并添加如下代码
from . import sharingan
if __name__ == "__main__":
sharingan.main()
5.2 参数化
并且作为一个工具,命令参数也是必不可少的。而在这里我们更推荐您使用 click 模块来添加参数,相比 argparse 着实方便很多
import click
import XXX
@click.command()
@click.argument("name") # 必要的名称
@click.option("--proxy_uri",default="http://127.0.0.1:1080") # 其他参数
def main():
XXX(name,proxy_uri).xx()
于是我们就可以通过如下代码方式来运行了
python3 -m sharingan ruanyf --proxy_uri=""
5.3 代码整理
我不知道有多少同学会觉得自己的代码规范有待提升
而在这方面 black 及 isort 分别能帮你完成代码整理及import整理
python3 -m pip install black isort
isort */*.py && black ./
并且在代码出现较语法错误的时候,black 将报错
5.4 项目图标
这也是我最近才想起来要用并搜索到的资源分享给大家
http://patorjk.com/software/taag
0x06 Github自动化
如果你经常在使用github做一些开发的话,这个项目你一定需要知道下
https://github.com/sdras/awesome-actions
它里面包含了许多非常好用的 Action,而我们今天聊得主要是发布到 PYPI 及在每次 push 后自动测试程序并发送提醒到 Telegram
6.1 自动发布
首先我们在本地项目下新建一个名为 setup.py 文件,并按照规范填入相关信息
import setuptools
with open("README.md", "r") as fh: # 默认读取readme
long_description = fh.read()
setuptools.setup(
name="项目名称",
version="项目版本例如 0.0.4",
author="作者名称",
author_email="作者邮箱链接",
description="项目简介",
long_description=long_description,
long_description_content_type="text/markdown",
url="项目主页链接",
packages=setuptools.find_packages(),
classifiers=[
"Programming Language :: Python :: 3.8",
...
], # 这里填的是相关的项目状态标识符
python_requires=">=3.8",
install_requires=[
"python_box==4.2.3",
"requests_html==0.10.0",
...
], # 这里填写的是相关项目的依赖
)
或许有同学会问,这个依赖(install_requires)该怎么填写。
我们会推荐使用 pipreqs 来一键生成,运行如下命令将生成一个 requirements.txt 的文件,然后我们摘抄进去就可以了。
python3 -m pip install pipreqs
pipreqs ./ --force
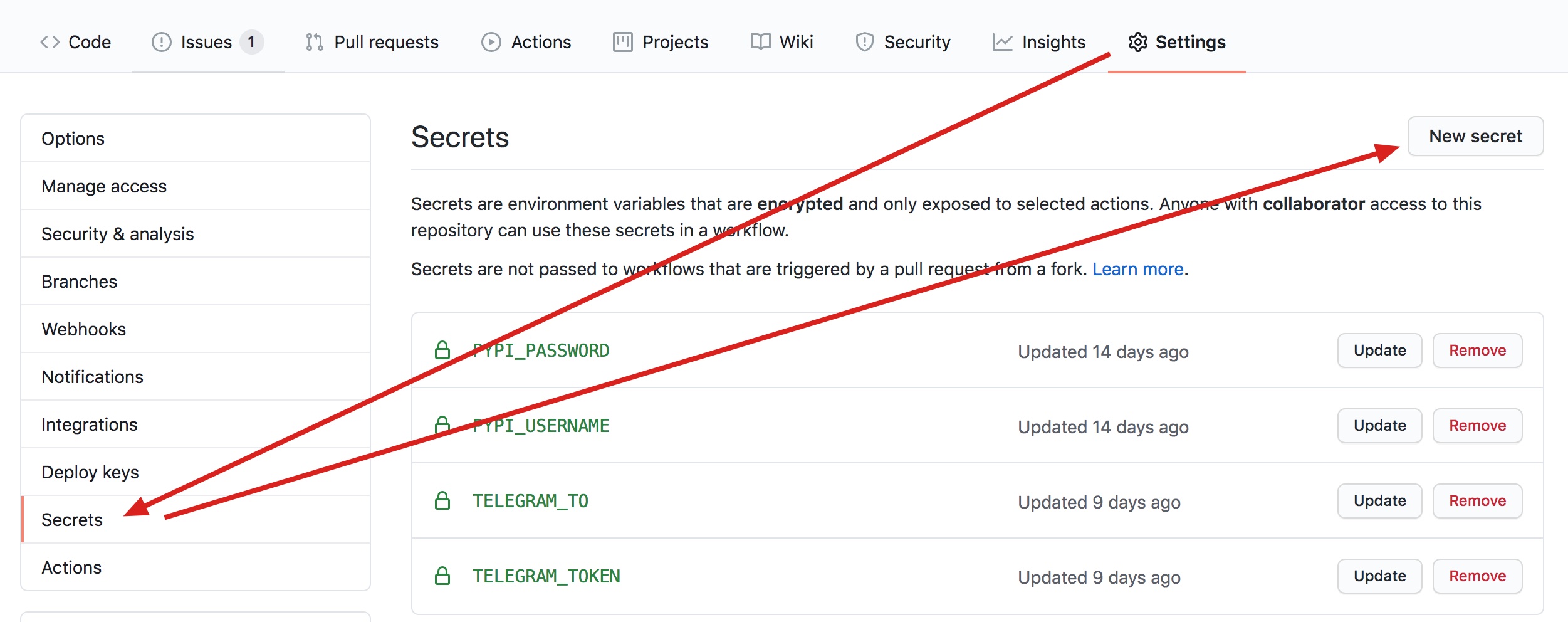
在发布前,请确认setup.py 已经提交至Github且保证您已经注册了 pypi ,并通过邮箱认证。 然后我们将账号信息填入 Github 个人设定
接下来我们进入 Action 界面下并选择官方的上传方法
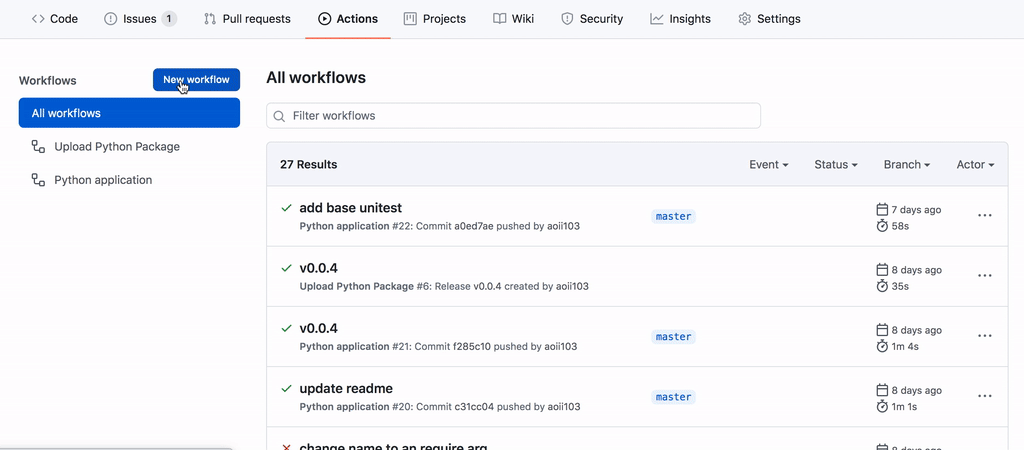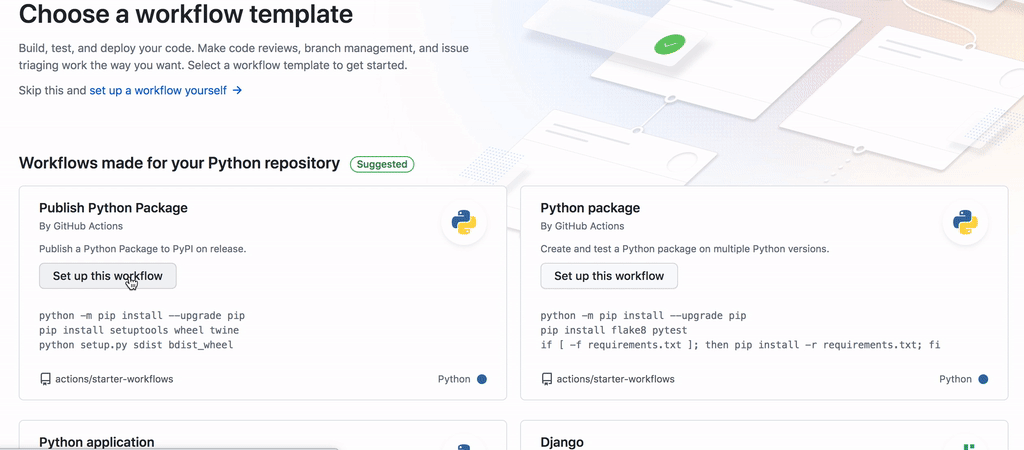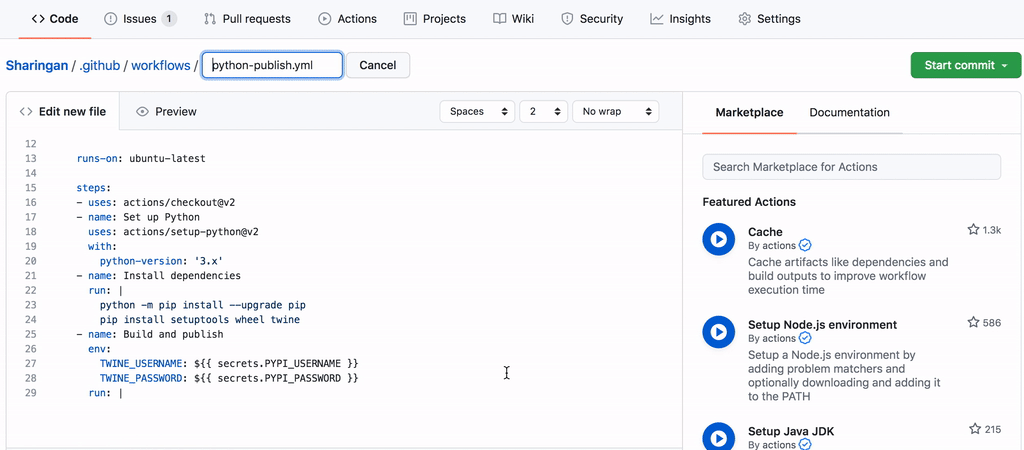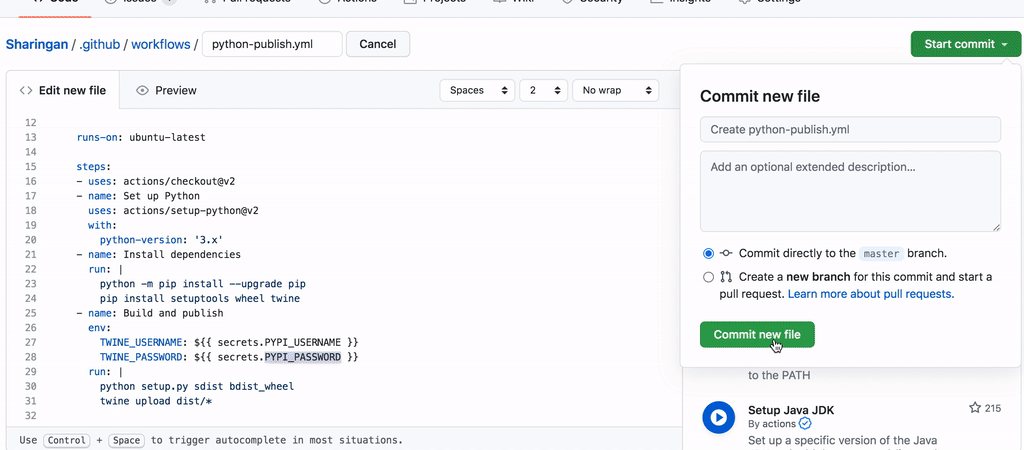
我们按下 Commit 就创建了这一步流程。然后我们需要转到主页并进入 release 以发布新版本
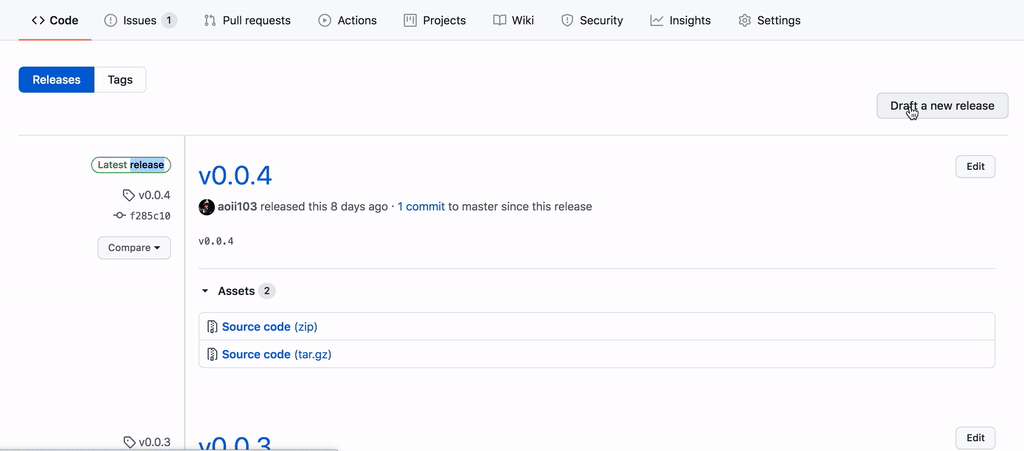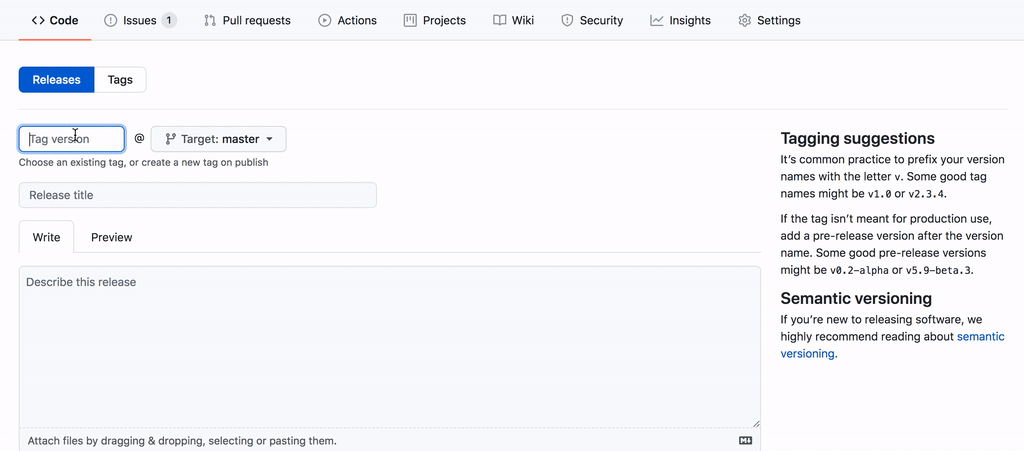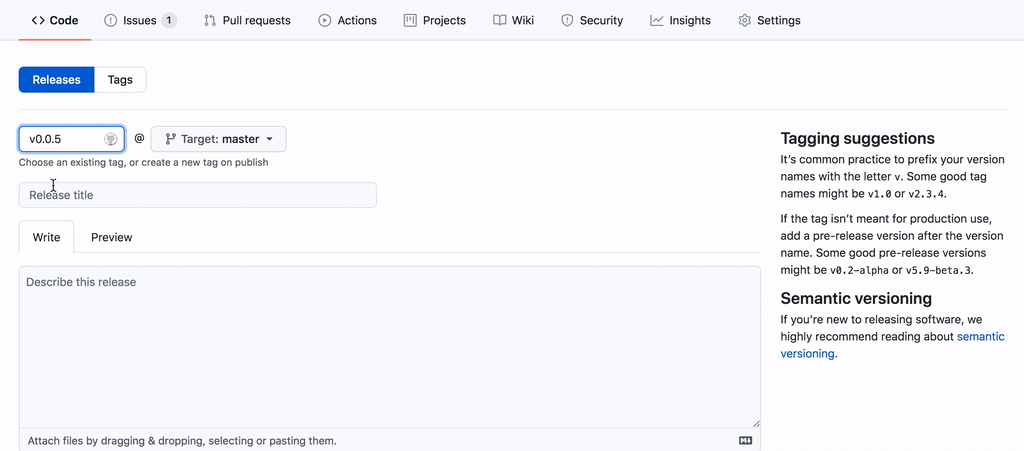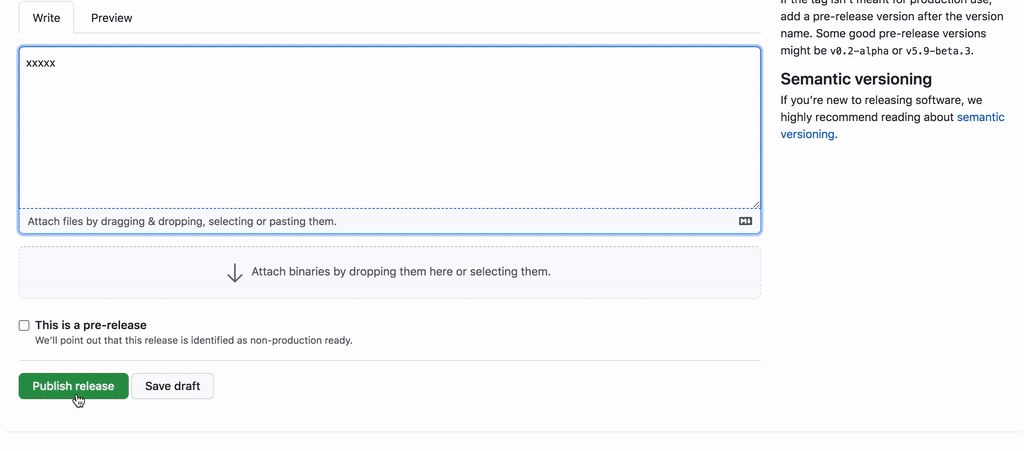
然后 Action 就开始工作了,我们可以进入到该界面查看详情。如果不去看的话,也只有报错才会接收到邮件提醒

6.2 测试及提醒
这里我们需要创建好telegram机器人,关于怎么创建我下次再说吧写累了。。这里写下文字版的
- Search –>
BotFather记得要后面带个✨的那个 - 然后输入一连串命令
/start /newbot- 给自己新的
robot取个昵称 - 然后会再让您给这个
robot取个用户名,注意:用户名存在唯一性 - 顺利的话下一句会告诉你
robot创建成功 并且token在Use this token to access the HTTP API:之下 - 接下来我们需要创建一个组并将自己和
robot都拉进去,然后再里面发个消息 - 最后我们访问
https://api.telegram.org/bot[token]/getupdates,获取其中的chat中的ID,也就是房间号
然后我们同样把 TOKEN 及 ID(对应 TO ) 填入到 Setting 的 Secure中
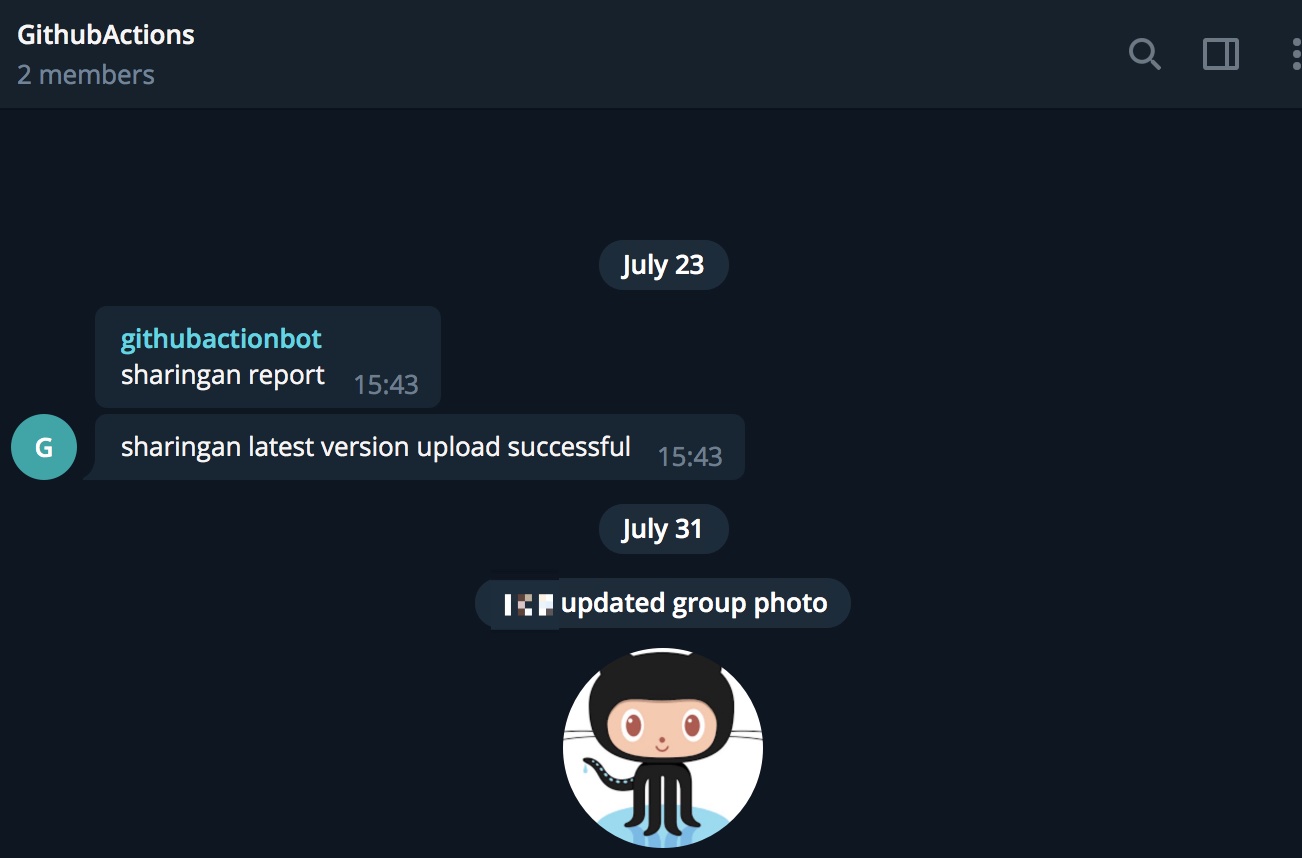
最后在Action 文件中追加如下内容并保存,即可添加测试及提醒功能
- name: Auto Test
run: |
python -m sharingan ruanyf --no_proxy
- name: Send result message
uses: appleboy/telegram-action@master
with:
to: ${{ secrets.TELEGRAM_TO }}
token: ${{ secrets.TELEGRAM_TOKEN }}
message: sharingan report
目前小编也正在积极得开发中,支持更多信息截取的站点也将越来越多,尽情期待 ~
