快速实现暗网交易监控

暗网或许对大多数人来说都是一个陌生的名词,但对于一个安全人员却是必不可少的一样的东西。暗网之内鱼龙混杂,内含的活动内容也是参差不齐。
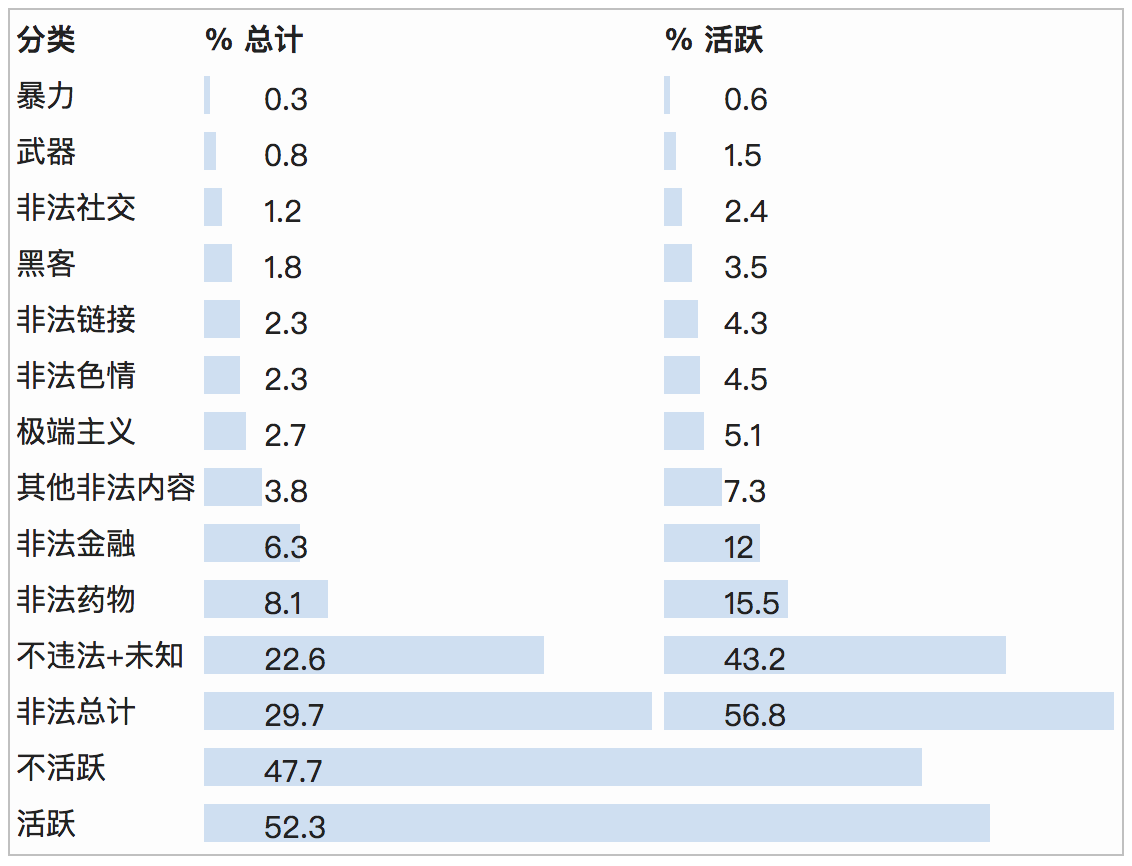
其中不乏各类的交易黑市,且交易内容也让人触目惊心。(护眼)
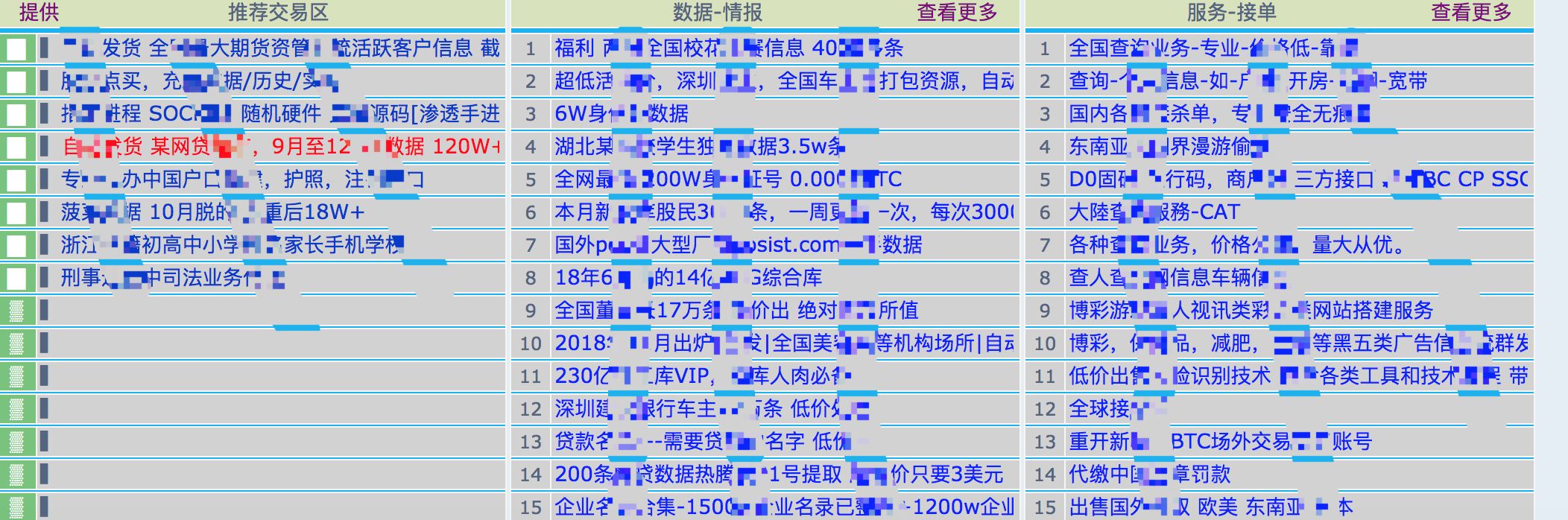
于是我们针对 deepmix2z2ayzi46.onion 暗网中文网编写了一个监控爬虫作为实践案例。
功能简要
- 自动注册
- 自动登录
- 防封禁策略
- ORM交互
- 事件详情/样本信息录入
- 事件提醒(telegram)
逻辑脑图
首先放出整个程序的逻辑图。
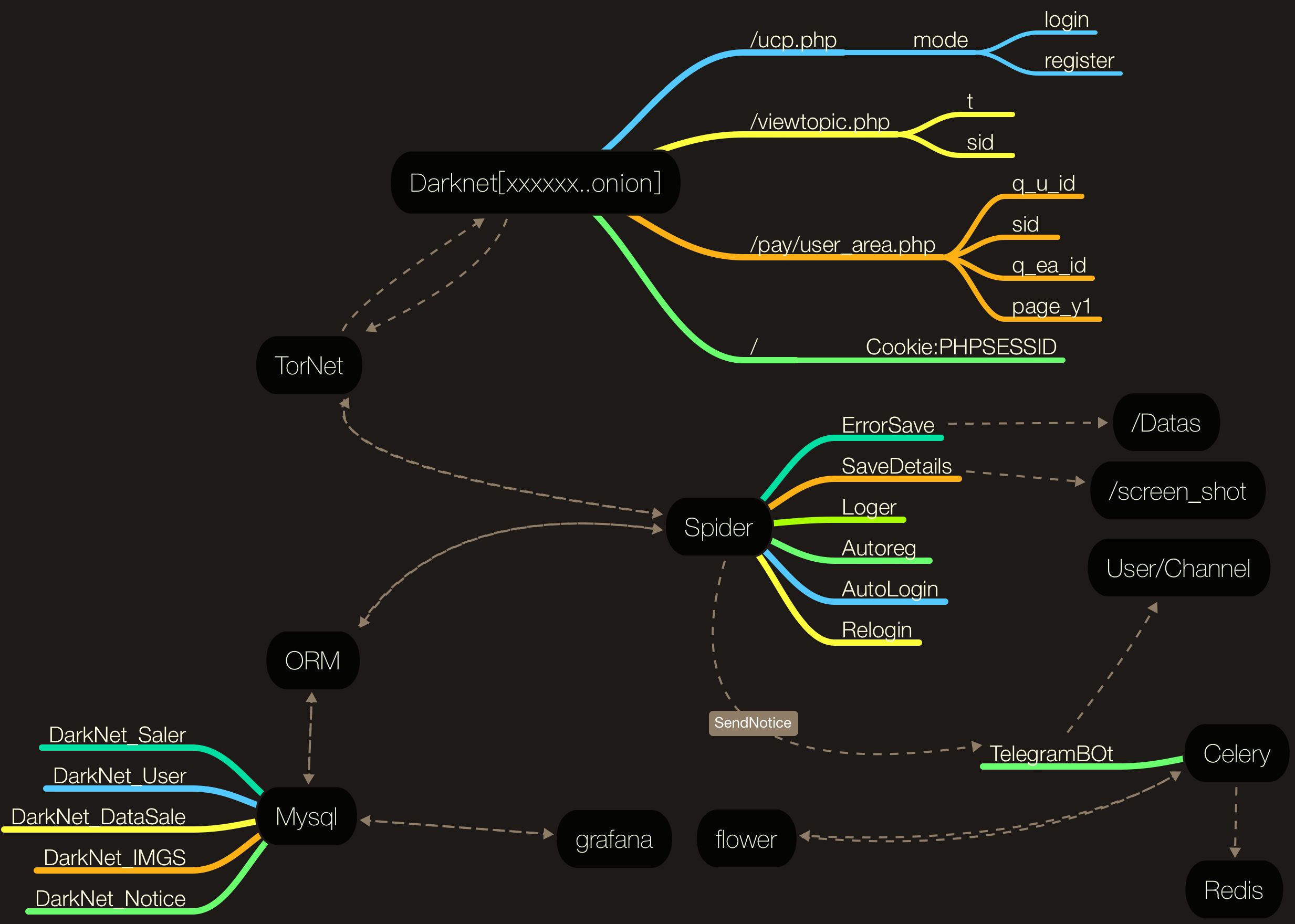
分析过程
下面我们简单讲一下该网站的业务逻辑,在进入该网站后网站以一个 *PHPSESSID*Cookie 作为用户整个生命周期的身份ID,过期时间为1小时,且不会自动延长。

只有靠再次登录才能刷个新的身份。那么在这里,我们需要设定一个Session会话来自动处理这个cookie。并配置socks5代理,关于tor的安装不再赘述。
self.session = requests.Session()
self.session.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Referer": "http://bmp3qqimv55xdznb.onion/index.php",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
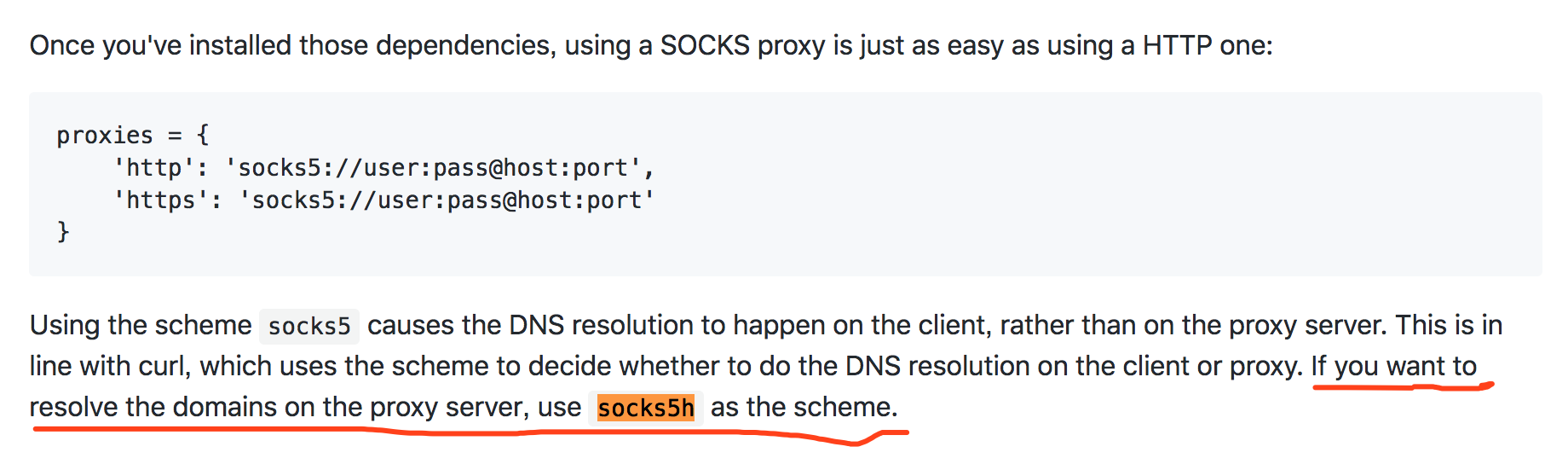
self.proxy_url = 'socks5h://127.0.0.1:9150'
self.session.proxies = {
'https': self.proxy_url,
'http': self.proxy_url
}
或许有同学会注意到这里使用的是 socks5h:// 协议,那么 Requests 模块文档中有注解。因为常规DNS服务器并不能解析*.onion地址而Tor网络可以。
而后我们需要注册,这里要注意的在正式进入注册界面之前需要先同意一个xxx协议,而这过程为一个Post请求。
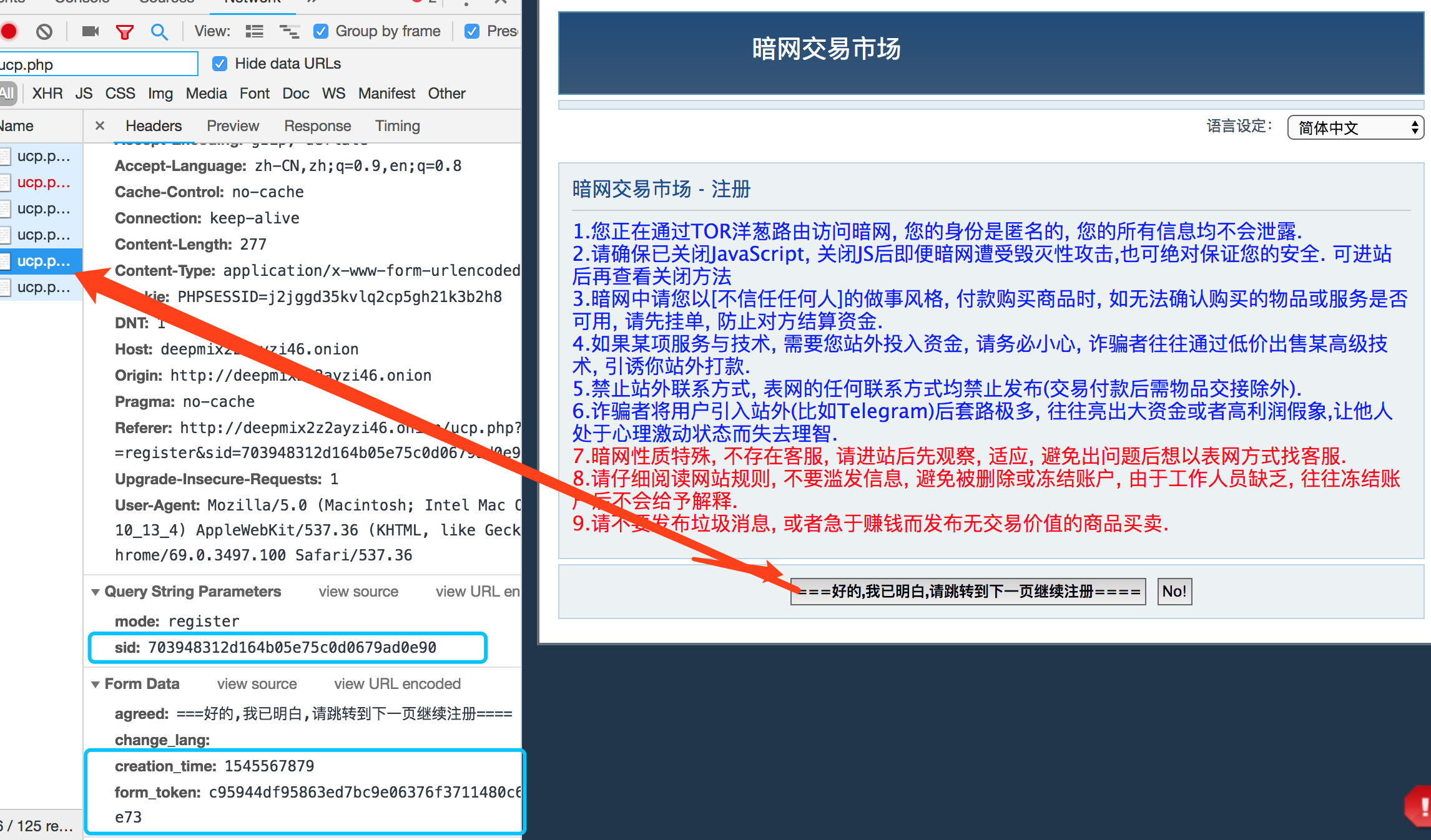
并且根据多次测试得出,如果不先发送该请求,则无法进入注册界面。考虑到这里使用的为Form Data,那么源数据就直接存在于HTML中。
因后续注册,登录均使用Form,表单位置不再赘述
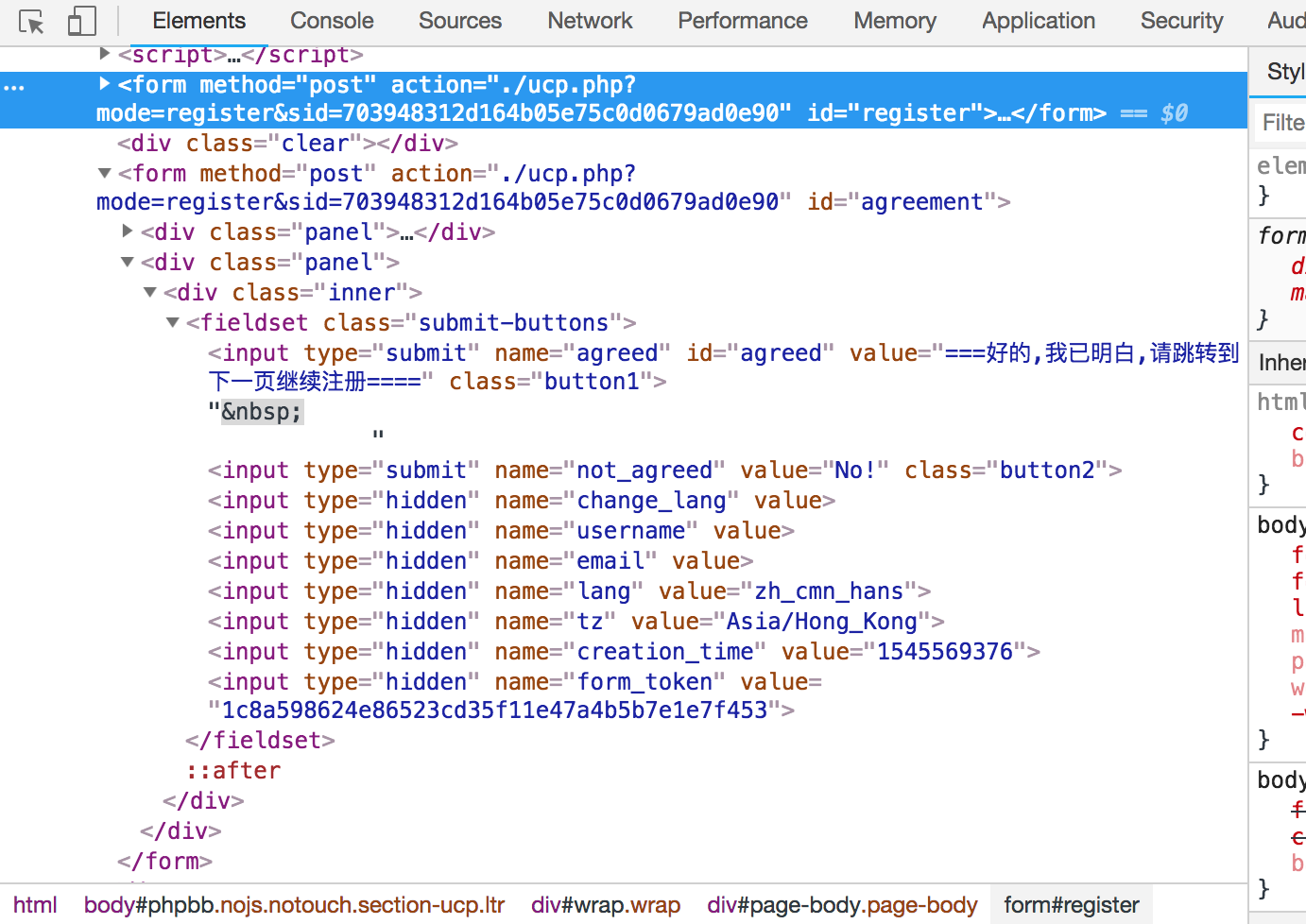
于是我们使用css selector语法来取到各个字段,通过正则取到sid
# 取到sid
self.sid = re.findall('sid=(.*?)"', step1resp)[0]
# 取到token
token = step1('input[name="form_token"]').attr('value')
# 取到creation_time
creation_time = step1('input[name="creation_time"]').attr('value')
# 生成URL
url = f"http://{self.domain}/ucp.php?mode=register&sid={self.sid}"
# 发送请求
step2resp = self.session.post(url, data={
"agreed": "===好的,我已明白,请跳转到下一页继续注册====",
"change_lang": "",
"creation_time": creation_time,
"form_token": token
}, headers=headers)
接下来我们成功得进入到了注册界面,这里要注意的是用户名密码需要同时包含大小写字符及数字,范围6-20,于是我们准备一个随机密码生成器
@staticmethod
def RandomKey(length=20):
return ''.join((random.choice(random.choice((string.ascii_uppercase, string.ascii_lowercase, ''.join(map(str, range(0, 9)))))) for i in range(1, length)))
并模拟注册过程。
# 获取第二步的resp内容
step2 = jq(step2resp.text)
# 取到新token
token = step2('input[name="form_token"]').attr('value')
# 取到创建时间
creation_time = step2('input[name="creation_time"]').attr('value')
# 随机账户
self.usr = self.RandomKey()
self.pwd = self.RandomKey()
# 生成payload
data = {
"username": self.usr,
"new_password": self.pwd,
"password_confirm": self.pwd,
"email": "[email protected]",
"lang": "zh_cmn_hans",
"tz_date": "UTC+08:00+-+Asia/Brunei+-+" + moment.now().format("DD+MM月+YYYY,+HH:mm"),
"tz": "Asia/Hong_Kong",
"agreed": "true",
"change_lang": "0",
"submit": " 用户名与密码已填好,+点此提交 ",
"creation_time": creation_time,
"form_token": token
}
# 发送注册请求
resp = self.session.post(url, data=data, headers=headers)
# 判断是否注册成功,失败则触发retry重新注册
assert '感谢注册' in resp.text
# 成功则保存账户
DarkNet_User.create(**{
'user': self.usr,
'pwd': self.pwd
})
然后以下是实际注册效果。因为使用的是佛系注册策略,所以有那么多。。
在注册完成之后我们需要开始进行登录操作。
# 登录URL
url = f'http://{self.domain}/ucp.php?mode=login'
# 封装payload
data = {
"username": self.usr,
"password": self.pwd,
"login": "登录",
"redirect": f"./index.php&sid={self.sid}"
}
# 发送登录
resp = self.session.post(url, data=data, verify=False, timeout=120)
# 判断是否成功登录
if self.usr not in resp.text:
# 如果被封禁则拉黑该账户并重新注册
if "已被封禁" in resp.text:
DarkNet_User.update({
"useful": False
}).where(DarkNet_User.user == self.usr).execute()
self.Reg()
# 注册完成触发retry
raise ValueError
接下来我们就取到了登录后的响应界面也就是主页,这里我们可以看到栏目按 .ad_div_b来分布。
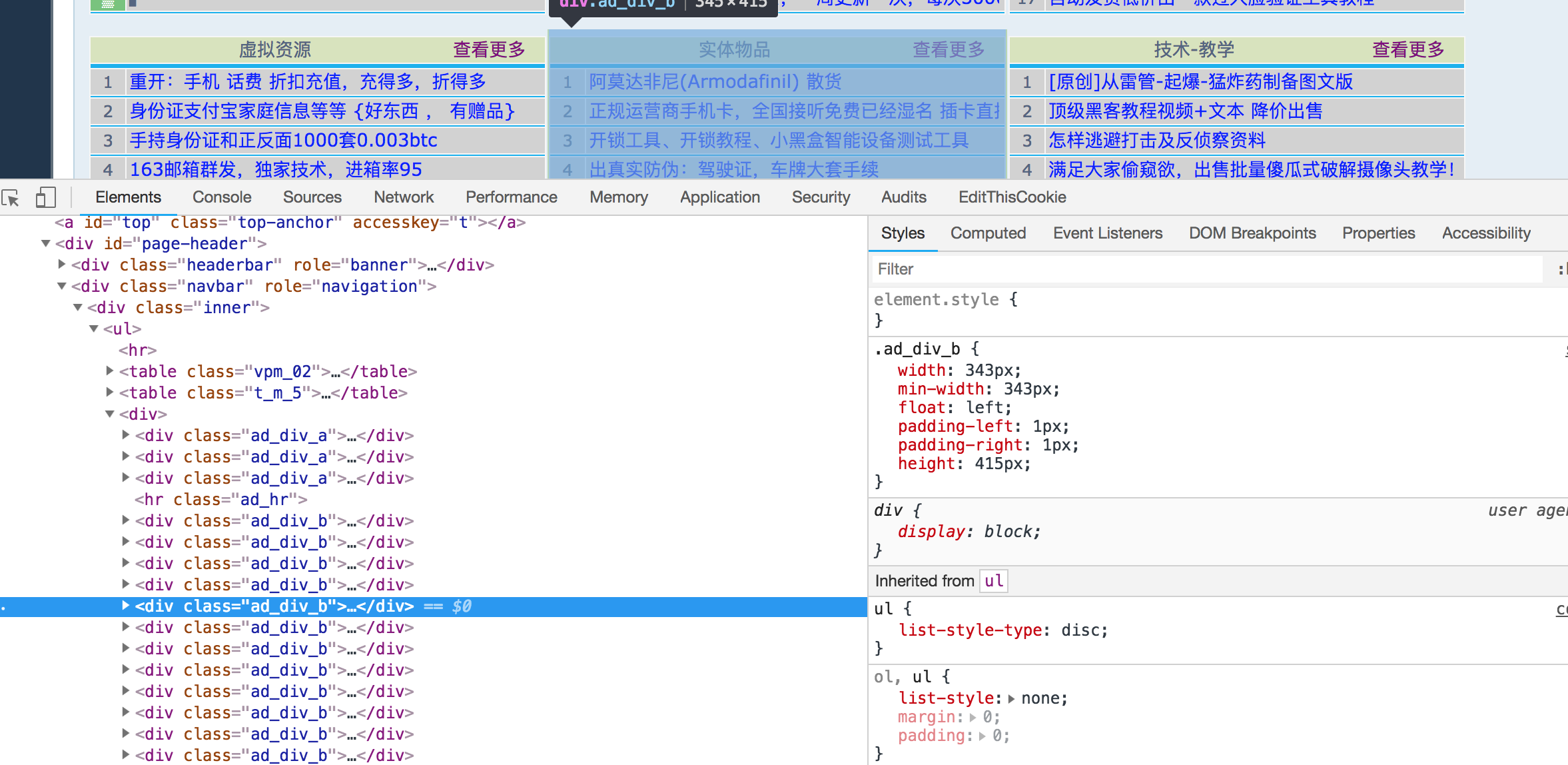
并且在查看更多选项为该栏目的详情首页。那么我通过如下代码获取全部的类型
self.types = {item('.index_list_title').attr('href').split('=')[1].split('&')[0]: item('tr:nth-child(1) > td').text().split()[0] for item in jq(resp.text)('.ad_table_b').items()}

然后我们迭代这些类型,并将其qeaid、页码page及其他参数代入模板URL,以抓取栏目最大页数及详细列表。
http://{self.domain}/pay/user_area.php?page_y1={page}&q_u_id=0&m_order=&q_ea_id={qeaid}&sid={self.sid}#page_y1
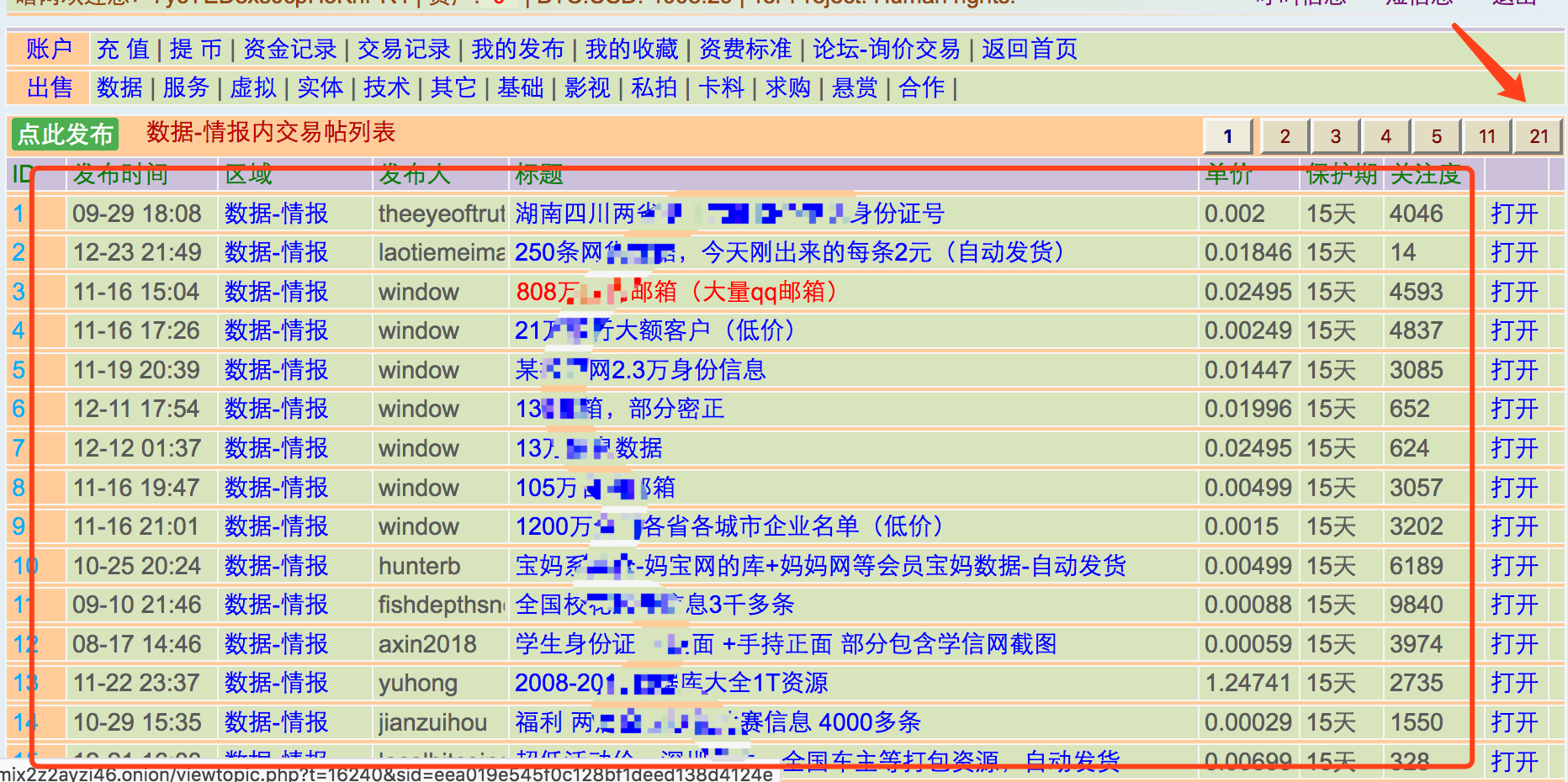
在获取页码的时候,我们需要将字符串做一个split+join操作以去除所有的分隔符。
根据分析界面结果得出 table.m_area_a tr路径下的每个div.length_400>a元素的href不为空,则为一条数据。根据这样的规则我们编写如下代码,并获取部分基础数据。
for item in jqdata('table.m_area_a tr').items():
detailPath = item('div.length_400>a').attr('href')
if detailPath:
# 组合URL
detailsURL = urljoin(resp.url, detailPath)
self.GetDetails(detailsURL, {
# 保护期,默认一般都为15天
'lines': FixNums(item('td:nth-child(7)').text().replace('天', '')),
# 热度,关注人数
'hot': FixNums(item('td:nth-child(8)').text()),
# 事件标题
'title': item('td:nth-child(5)').text(),
# 类型
'area': item('td:nth-child(3)').text()
})
在获取箭头指示最大页数后,不断翻页迭代上面的过程以爬取全部页码及类型。
需要注意一点,我们获取到的不一定是真实最大页码-。-,在爬行的时候需要判断结果列表是否为空。如果为空则为到达尾页需break跳出
得到列表中的每条数据之后,为了获取详情,我们还需要进一步的其详情界面进行抓取。步骤依然为根据css selector路径来取到数据,不再赘述。

部分用户填写的出售数量大的超过了限制(过于夸张),这里我们需要默认一个最大值进行处理
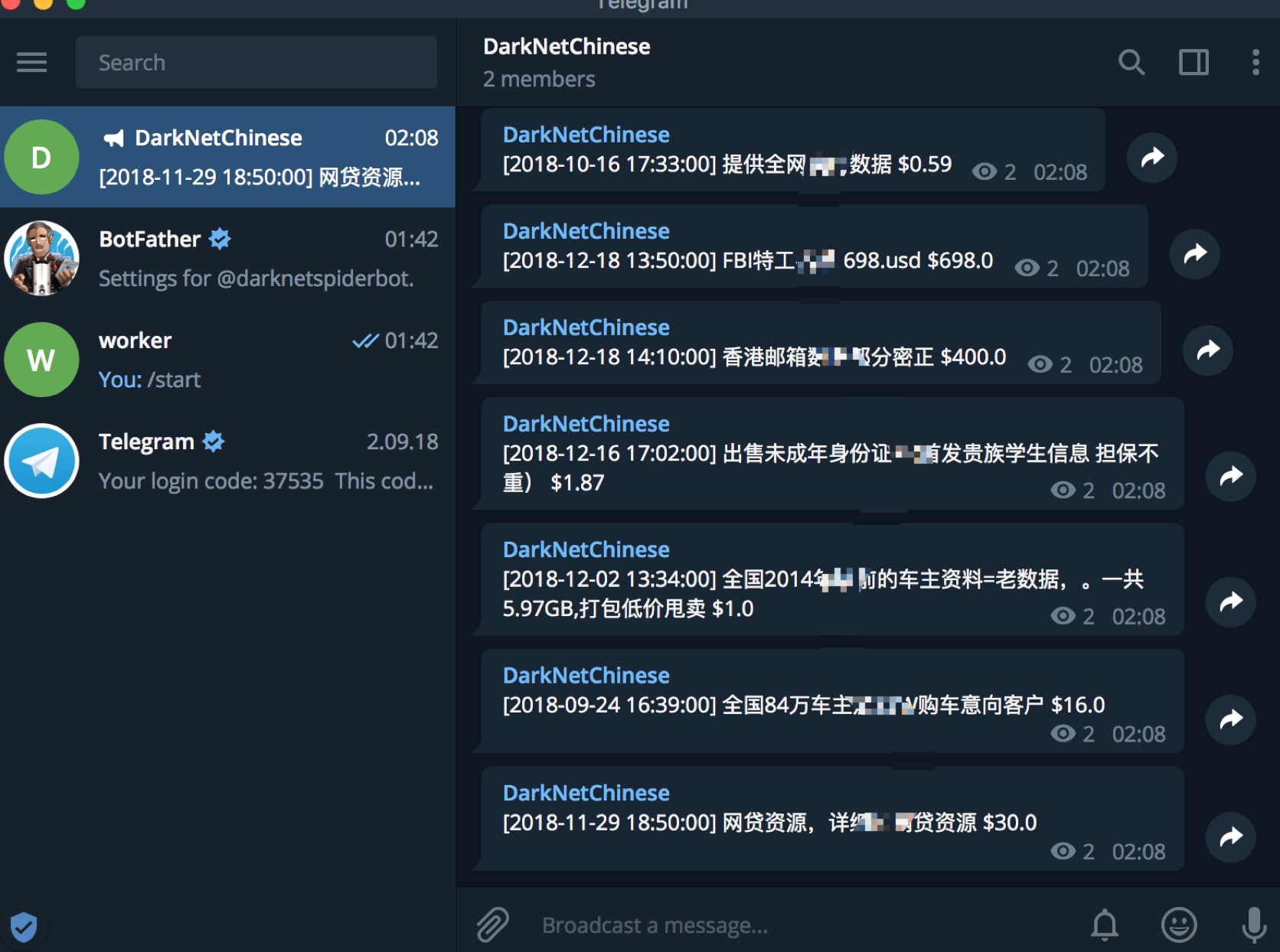
当然在取到数据的同时,我们需要判断该数据是否为允许提醒范围内的数据,如果是则通过telebot发送给channel。
# 如果时间A 是在相对今天B天前的0点之前出现,则发送
if moment.date(A) > moment.now().replace(hours=0, minutes=0, seconds=0).add(days=B):
telegram.delay(msg, sid, Config.darknetchannelID)
然后我们的客户端就收到了及时的提醒,于是整个项目就完成的差不多了。
加入channel: https://t.me/fordarknetspiderbot
ORM模型
首先我们通过pymysql连接数据库并查询是否存在该库,没有则创建,编码UTF8MB4。
try:
con = pymysql.connect(**Links)
with con.cursor() as cursor:
cursor.execute(
f'create database {Config.mysql_db} character set UTF8mb4 collate utf8mb4_bin')
con.close()
except pymysql.err.ProgrammingError as e:
if '1007' in str(e):
pass
except Exception as e:
raise e
在完成创建后我们通过peewee来ORM驱动生成相应表格,以下是相应表的简介。
DarkNet_Saler售卖者信息DarkNet_User爬虫用户池DarkNet_IMGS数据说明信息 (鸡肋)DarkNet_Notice消息发送记录DarkNet_DataSale信息详情
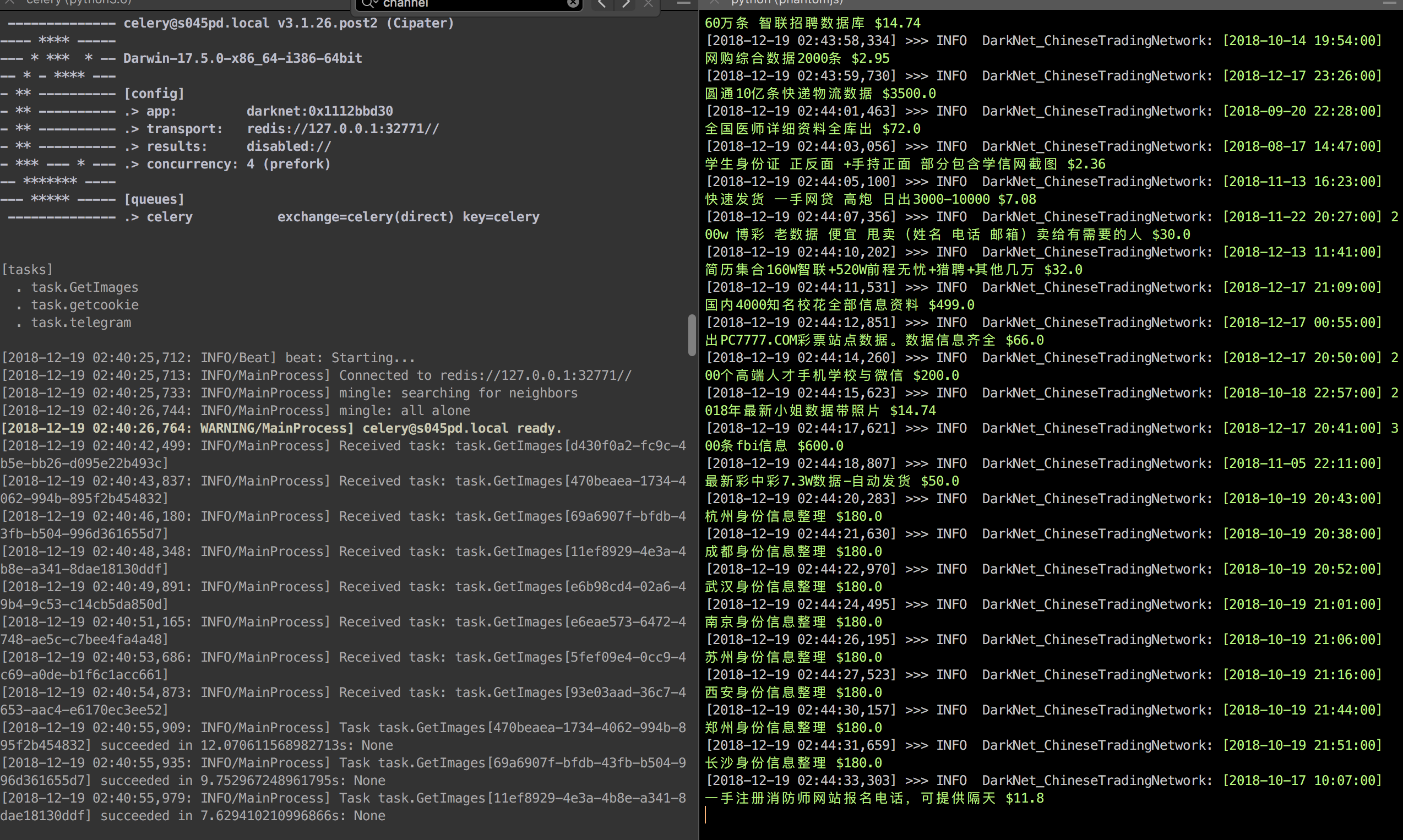
代码运行结果
可以看到,爬虫本身以及celery运行状态良好。
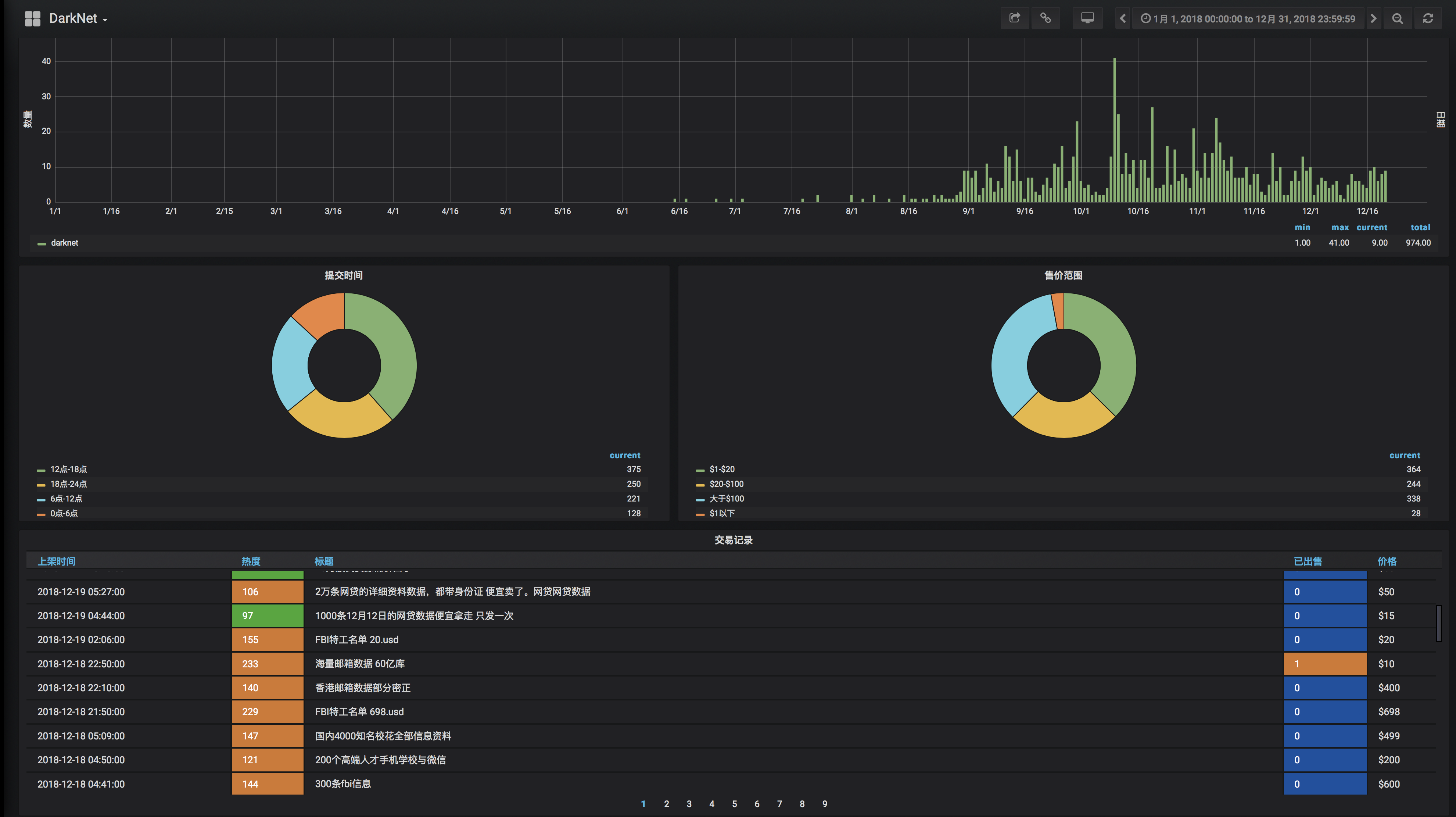
Grafana可视化
为了让数据结果更加直观,我们通过grafana快速构建展示界面,当然这也是偷懒的操作。后期会针对grafana专门写一篇,本篇不再赘述。
案例地址: grafana_demo
最后,细心的同学是否有发现文章开头的贴图有些,特别么-v-?
